Orchestrated ETL Design Pattern for Apache Spark and Databricks
This article describes ideas based on existing software design patterns that can be applied to designing data processing libraries to be used by Databricks
As a data platform grows bigger it becomes harder and more complex to maintain a large set of Notebooks. Although, reusing code between Notebooks is possible using the %run command, it is neither elegant nor efficient.
The goal in mind when writing this is to move as much code regarding ETL operations as possible, if not all, away from Notebooks and into a Python library. This library should also contain reusable components for ingesting data in various formats from various data sources into a variety of data stores
Databricks Notebooks should be used for only 3 things:
- Data exploration
- Executing library code
- Interacting with the dbutils API (i.e. reading secrets or setting up widgets for parameterized jobs)
All components must be designed with unit and integration testing in mind, and tests must execute in the CI/CD pipeline
In the past, some of us have used and implemented variations on the Model-View-Whatever (MVC, MVP, MVVM, etc) design pattern. Such patterns solve the problems regarding separating concerns between the following:
- Data layer
- Business logic
- Application logic
- User interface
A similar pattern can be derived for separating the following concerns:
- Extraction
- Transformation
- Loading
The OETL Design Pattern
Short for Orchestrated Extract-Transform-Load is a pattern that takes the ideas behind variations of the Model-View-Whatever design pattern
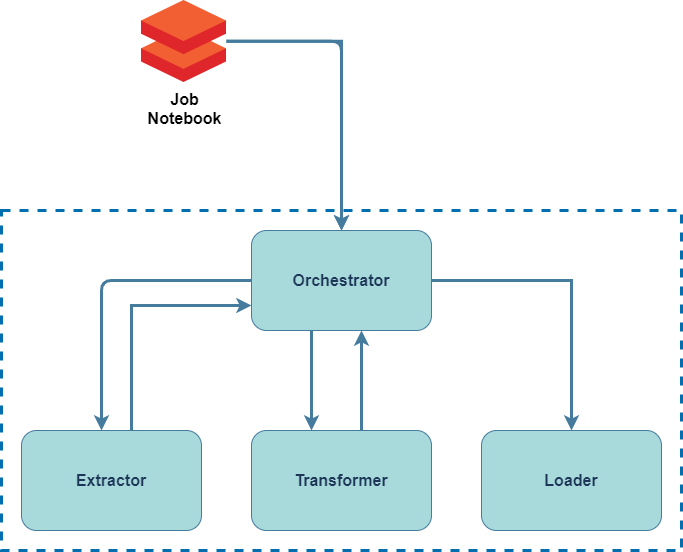
The Orchestrator is responsible for conducting the interactions between the Extractor -> Transformer -> Loader.
The Ochestrator reads data from the Extractor then uses the result as a parameter to calling the Transformer and saves the transformed result into the Loader. The Transformer can be optional as there are scenarios where data transformation is not needed, i.e. raw data ingestion to the landing zone (bronze)
Each layer may have a single or multiple implementations, and this is handled automatically in the Orchestrator
In Python, an example of an Orchestrator with single implementations of the Extractor, Transformer, and Loader would look something like this:
class Orchestrator:
def __init__(self,
extractor: Extractor,
transformer: Transformer,
loader: Loader):
self.loader = loader
self.transformer = transformer
self.extractor = extractor
def execute(self):
df = self.extractor.read()
df = self.transformer.process(df)
self.loader.save(df)
ATC-DataPlatform
A framework for this design pattern is implemented in a Python Library called atc-dataplatform available from PyPi
pip install atc-dataplatform
Orchestration Fluent Interface
atc-dataplatform provides common simple implementations and base classes for implementing the OETL design pattern.
To simplify object construction, this library provides the Orchestrator fluent interface from atc.etl
from atc.etl import Extractor, Transformer, Loader, Orchestrator
(Orchestrator()
.extract_from(Extractor())
.transform_with(Transformer())
.load_into(Loader())
.execute())
Usage examples:
Here are some example usages and implementations of the ETL class provided
Example-1
Here’s an example of reading data from a single location, transforming it once and saving to a single destination. This is the most simple elt case, and will be used as base for the below more complex examples.
import pyspark.sql.functions as f
from pyspark.sql import DataFrame
from pyspark.sql.types import IntegerType
from atc.etl import Extractor, Transformer, Loader, Orchestrator
from atc.spark import Spark
class GuitarExtractor(Extractor):
def read(self) -> DataFrame:
return Spark.get().createDataFrame(
Spark.get().sparkContext.parallelize(
[
("1", "Fender", "Telecaster", "1950"),
("2", "Gibson", "Les Paul", "1959"),
("3", "Ibanez", "RG", "1987"),
]
),
"""
id STRING,
brand STRING,
model STRING,
year STRING
""",
)
class BasicTransformer(Transformer):
def process(self, df: DataFrame) -> DataFrame:
print("Current DataFrame schema")
df.printSchema()
df = df.withColumn("id", f.col("id").cast(IntegerType()))
df = df.withColumn("year", f.col("year").cast(IntegerType()))
print("New DataFrame schema")
df.printSchema()
return df
class NoopLoader(Loader):
def save(self, df: DataFrame) -> None:
df.write.format("noop").mode("overwrite").save()
df.printSchema()
df.show()
print("ETL Orchestrator using a single simple transformer")
etl = (
Orchestrator()
.extract_from(GuitarExtractor())
.transform_with(BasicTransformer())
.load_into(NoopLoader())
)
etl.execute()
The code above produces the following output:
Original DataFrame schema
root
|-- id: string (nullable = true)
|-- brand: string (nullable = true)
|-- model: string (nullable = true)
|-- year: string (nullable = true)
New DataFrame schema
root
|-- id: integer (nullable = true)
|-- brand: string (nullable = true)
|-- model: string (nullable = true)
|-- year: integer (nullable = true)
+---+------+----------+----+
| id| brand| model|year|
+---+------+----------+----+
| 1|Fender|Telecaster|1950|
| 2|Gibson| Les Paul|1959|
| 3|Ibanez| RG|1987|
+---+------+----------+----+
Example-2
Here’s an example of having multiple Transformer implementations that is reused to change the data type of a given column,
where the column name is parameterized.
import pyspark.sql.functions as f
from pyspark.sql import DataFrame
from pyspark.sql.types import StructType, StructField, IntegerType, StringType
from atc.etl import Extractor, Transformer, Loader, Orchestrator
from atc.spark import Spark
class GuitarExtractor(Extractor):
def read(self) -> DataFrame:
return Spark.get().createDataFrame(
Spark.get().sparkContext.parallelize(
[
("1", "Fender", "Telecaster", "1950"),
("2", "Gibson", "Les Paul", "1959"),
("3", "Ibanez", "RG", "1987"),
]
),
StructType(
[
StructField("id", StringType()),
StructField("brand", StringType()),
StructField("model", StringType()),
StructField("year", StringType()),
]
),
)
class IntegerColumnTransformer(Transformer):
def __init__(self, col_name: str):
super().__init__()
self.col_name = col_name
def process(self, df: DataFrame) -> DataFrame:
df = df.withColumn(self.col_name, f.col(self.col_name).cast(IntegerType()))
return df
class NoopLoader(Loader):
def save(self, df: DataFrame) -> None:
df.write.format("noop").mode("overwrite").save()
df.printSchema()
df.show()
print("ETL Orchestrator using multiple transformers")
etl = (
Orchestrator()
.extract_from(GuitarExtractor())
.transform_with(IntegerColumnTransformer("id"))
.transform_with(IntegerColumnTransformer("year"))
.load_into(NoopLoader())
)
etl.execute()
Example-3
Here’s an example of having multiple Extractor implementations and applying transformations using
the process_many method.
The read() function in Extractor will return a dictionary that uses the type name of the Extractor
as the key, and a DataFrame as its value, the used kan can be overridden in the constructor.
Transformer provides the function process_many(dataset: {}) and returns a single DataFrame.
import pyspark.sql.functions as f
from pyspark.sql import DataFrame
from pyspark.sql.types import StructType, StructField, StringType
from atc.etl import Extractor, Loader, Orchestrator, Transformer
from atc.spark import Spark
class AmericanGuitarExtractor(Extractor):
def read(self) -> DataFrame:
return Spark.get().createDataFrame(
Spark.get().sparkContext.parallelize(
[
("1", "Fender", "Telecaster", "1950"),
("2", "Gibson", "Les Paul", "1959"),
]
),
StructType(
[
StructField("id", StringType()),
StructField("brand", StringType()),
StructField("model", StringType()),
StructField("year", StringType()),
]
),
)
class JapaneseGuitarExtractor(Extractor):
def __init__(self):
super().__init__(dataset_key="japanese")
def read(self) -> DataFrame:
return Spark.get().createDataFrame(
Spark.get().sparkContext.parallelize(
[("3", "Ibanez", "RG", "1987"), ("4", "Takamine", "Pro Series", "1959")]
),
StructType(
[
StructField("id", StringType()),
StructField("brand", StringType()),
StructField("model", StringType()),
StructField("year", StringType()),
]
),
)
class CountryOfOriginTransformer(Transformer):
def process_many(self, dataset: {}) -> DataFrame:
usa_df = dataset["AmericanGuitarExtractor"].withColumn("country", f.lit("USA"))
jap_df = dataset["japanese"].withColumn("country", f.lit("Japan"))
return usa_df.union(jap_df)
class NoopLoader(Loader):
def save(self, df: DataFrame) -> None:
df.write.format("noop").mode("overwrite").save()
df.printSchema()
df.show()
print("ETL Orchestrator using multiple extractors")
etl = (
Orchestrator()
.extract_from(AmericanGuitarExtractor())
.extract_from(JapaneseGuitarExtractor())
.transform_with(CountryOfOriginTransformer())
.load_into(NoopLoader())
)
etl.execute()
The code above produces the following output:
root
|-- id: string (nullable = true)
|-- brand: string (nullable = true)
|-- model: string (nullable = true)
|-- year: string (nullable = true)
|-- country: string (nullable = false)
+---+--------+----------+----+-------+
| id| brand| model|year|country|
+---+--------+----------+----+-------+
| 1| Fender|Telecaster|1950| USA|
| 2| Gibson| Les Paul|1959| USA|
| 3| Ibanez| RG|1987| Japan|
| 4|Takamine|Pro Series|1959| Japan|
+---+--------+----------+----+-------+
Example-4
Here’s an example of data raw ingestion without applying any transformations.
from pyspark.sql import DataFrame
from atc.etl import Extractor, Loader, Orchestrator
from atc.spark import Spark
class GuitarExtractor(Extractor):
def read(self) -> DataFrame:
return Spark.get().createDataFrame(
Spark.get().sparkContext.parallelize(
[
("1", "Fender", "Telecaster", "1950"),
("2", "Gibson", "Les Paul", "1959"),
("3", "Ibanez", "RG", "1987"),
]
),
"""id STRING, brand STRING, model STRING, year STRING""",
)
class NoopLoader(Loader):
def save(self, df: DataFrame) -> None:
df.write.format("noop").mode("overwrite").save()
df.printSchema()
df.show()
print("ETL Orchestrator with no transformations")
etl = Orchestrator().extract_from(GuitarExtractor()).load_into(NoopLoader())
etl.execute()
Example-5
Here’s an example of having multiple Loader implementations that is writing the transformed data into multiple destinations.
import pyspark.sql.functions as f
from pyspark.sql import DataFrame
from pyspark.sql.types import StructType, StructField, IntegerType, StringType
from atc.etl import Extractor, Transformer, Loader, Orchestrator
from atc.spark import Spark
class GuitarExtractor(Extractor):
def read(self) -> DataFrame:
return Spark.get().createDataFrame(
Spark.get().sparkContext.parallelize(
[
("1", "Fender", "Telecaster", "1950"),
("2", "Gibson", "Les Paul", "1959"),
("3", "Ibanez", "RG", "1987"),
]
),
StructType(
[
StructField("id", StringType()),
StructField("brand", StringType()),
StructField("model", StringType()),
StructField("year", StringType()),
]
),
)
class BasicTransformer(Transformer):
def process(self, df: DataFrame) -> DataFrame:
print("Current DataFrame schema")
df.printSchema()
df = df.withColumn("id", f.col("id").cast(IntegerType()))
df = df.withColumn("year", f.col("year").cast(IntegerType()))
print("New DataFrame schema")
df.printSchema()
return df
class NoopSilverLoader(Loader):
def save(self, df: DataFrame) -> None:
df.write.format("noop").mode("overwrite").save()
class NoopGoldLoader(Loader):
def save(self, df: DataFrame) -> None:
df.write.format("noop").mode("overwrite").save()
df.printSchema()
df.show()
print("ETL Orchestrator using multiple loaders")
etl = (
Orchestrator()
.extract_from(GuitarExtractor())
.transform_with(BasicTransformer())
.load_into(NoopSilverLoader())
.load_into(NoopGoldLoader())
)
etl.execute()
Example-6
Using Example-2, Example-3 and Example-5 as reference,
any combinations for single/multiple implementations of Extractor, Transformer or Loader can be created.
Here’s an example of having both multiple Extractor, Transformer and Loader implementations.
It is important that the first transformer is a MultiInputTransformer when having multiple extractors.
import pyspark.sql.functions as f
from pyspark.sql import DataFrame
from pyspark.sql.types import StructType, StructField, IntegerType, StringType
from atc.etl import Extractor, Transformer, Loader, Orchestrator
from atc.spark import Spark
class AmericanGuitarExtractor(Extractor):
def read(self) -> DataFrame:
return Spark.get().createDataFrame(
Spark.get().sparkContext.parallelize(
[
("1", "Fender", "Telecaster", "1950"),
("2", "Gibson", "Les Paul", "1959"),
]
),
StructType(
[
StructField("id", StringType()),
StructField("brand", StringType()),
StructField("model", StringType()),
StructField("year", StringType()),
]
),
)
class JapaneseGuitarExtractor(Extractor):
def read(self) -> DataFrame:
return Spark.get().createDataFrame(
Spark.get().sparkContext.parallelize(
[("3", "Ibanez", "RG", "1987"), ("4", "Takamine", "Pro Series", "1959")]
),
StructType(
[
StructField("id", StringType()),
StructField("brand", StringType()),
StructField("model", StringType()),
StructField("year", StringType()),
]
),
)
class CountryOfOriginTransformer(Transformer):
def process_many(self, dataset: {}) -> DataFrame:
usa_df = dataset["AmericanGuitarExtractor"].withColumn("country", f.lit("USA"))
jap_df = dataset["JapaneseGuitarExtractor"].withColumn(
"country", f.lit("Japan")
)
return usa_df.union(jap_df)
class BasicTransformer(Transformer):
def process(self, df: DataFrame) -> DataFrame:
print("Current DataFrame schema")
df.printSchema()
df = df.withColumn("id", f.col("id").cast(IntegerType()))
df = df.withColumn("year", f.col("year").cast(IntegerType()))
print("New DataFrame schema")
df.printSchema()
return df
class NoopSilverLoader(Loader):
def save(self, df: DataFrame) -> None:
df.write.format("noop").mode("overwrite").save()
class NoopGoldLoader(Loader):
def save(self, df: DataFrame) -> None:
df.write.format("noop").mode("overwrite").save()
df.printSchema()
df.show()
print("ETL Orchestrator using multiple loaders")
etl = (
Orchestrator()
.extract_from(AmericanGuitarExtractor())
.extract_from(JapaneseGuitarExtractor())
.transform_with(CountryOfOriginTransformer())
.transform_with(BasicTransformer())
.load_into(NoopSilverLoader())
.load_into(NoopGoldLoader())
)
etl.execute()
Example-7
This example illustrates the use of an orchestrator as just another ETL step. The principle is called composit orchestration:
import pyspark.sql.functions as F
import pyspark.sql.types as T
from pyspark.sql import DataFrame
from pyspark.sql.types import IntegerType
from atc.etl import Extractor, Transformer, Loader, Orchestrator, dataset_group
from atc.spark import Spark
class AmericanGuitarExtractor(Extractor):
def read(self) -> DataFrame:
return Spark.get().createDataFrame(
Spark.get().sparkContext.parallelize(
[
("1", "Fender", "Telecaster", "1950"),
("2", "Gibson", "Les Paul", "1959"),
]
),
T.StructType(
[
T.StructField("id", T.StringType()),
T.StructField("brand", T.StringType()),
T.StructField("model", T.StringType()),
T.StructField("year", T.StringType()),
]
),
)
class JapaneseGuitarExtractor(Extractor):
def read(self) -> DataFrame:
return Spark.get().createDataFrame(
Spark.get().sparkContext.parallelize(
[
("3", "Ibanez", "RG", "1987"),
("4", "Takamine", "Pro Series", "1959"),
]
),
T.StructType(
[
T.StructField("id", T.StringType()),
T.StructField("brand", T.StringType()),
T.StructField("model", T.StringType()),
T.StructField("year", T.StringType()),
]
),
)
class CountryOfOriginTransformer(Transformer):
def process_many(self, dataset: dataset_group) -> DataFrame:
usa_df = dataset["AmericanGuitarExtractor"].withColumn("country", F.lit("USA"))
jap_df = dataset["JapaneseGuitarExtractor"].withColumn("country", F.lit("Japan"))
return usa_df.union(jap_df)
class OrchestratorLoader(Loader):
def __init__(self, orchestrator: Orchestrator):
super().__init__()
self.orchestrator = orchestrator
def save_many(self, datasets: dataset_group) -> None:
self.orchestrator.execute(datasets)
class NoopLoader(Loader):
def save(self, df: DataFrame) -> None:
df.write.format("noop").mode("overwrite").save()
df.printSchema()
df.show()
print("ETL Orchestrator using composit innter orchestrator")
etl_inner = (
Orchestrator()
.transform_with(CountryOfOriginTransformer())
.load_into(NoopLoader())
)
etl_outer = (
Orchestrator()
.extract_from(AmericanGuitarExtractor())
.extract_from(JapaneseGuitarExtractor())
.load_into(OrchestratorLoader(etl_inner))
)
etl_outer.execute()
If you find this interesting then you should definitely check out atc-dataplatform on Github