HttpTestGen - .http file testing framework for .NET
I’m excited to introduce HttpTestGen, a powerful .NET source generator that automatically converts .http files into fully functional C# test code. This innovative tool bridges the gap between API testing in IDEs (like Visual Studio Code with the REST Client extension) and automated testing in your .NET projects.
If you’ve been using .http files to test your APIs manually in Visual Studio or other IDEs, HttpTestGen takes this workflow to the next level by automatically generating unit tests from those same files. I’ve written about generating .http files from OpenAPI specs and running them as integration tests, and HttpTestGen completes the testing workflow by bringing those manual tests into your automated test suite.
What is HttpTestGen?
HttpTestGen is a .NET source generator that reads .http files in your test projects and automatically generates corresponding xUnit or TUnit test methods at compile time. The tool supports a comprehensive range of HTTP operations and includes sophisticated assertion capabilities for validating API responses.
Key Features
HttpTestGen offers a rich set of features designed to make API testing both powerful and intuitive:
- Automatic Test Generation: Transform
.httpfiles into xUnit or TUnit test code at compile time - Rich HTTP Support: Parse GET, POST, PUT, DELETE, PATCH, HEAD, OPTIONS, and TRACE methods
- Header Processing: Full support for HTTP headers including custom headers
- Request Bodies: Support for JSON, XML, and text request bodies
- Response Assertions: Validate expected status codes and response headers
- Multiple Test Frameworks: Generate tests for xUnit and TUnit
- Source Generator: Zero-runtime overhead with compile-time code generation
- IDE Integration: Works seamlessly with existing
.httpfiles in your IDE
Installation
Getting started with HttpTestGen is straightforward. The tool is available as NuGet packages for both xUnit and TUnit frameworks.
xUnit Generator
For xUnit-based projects, add the following package reference to your test project:
<PackageReference Include="HttpTestGen.XunitGenerator" Version="1.0.0">
<PrivateAssets>all</PrivateAssets>
<IncludeAssets>runtime; build; native; contentfiles; analyzers</IncludeAssets>
</PackageReference>
TUnit Generator
For TUnit-based projects, use this package reference:
<PackageReference Include="HttpTestGen.TUnitGenerator" Version="1.0.0">
<PrivateAssets>all</PrivateAssets>
<IncludeAssets>runtime; build; native; contentfiles; analyzers</IncludeAssets>
</PackageReference>
The PrivateAssets="all" ensures that the source generator is only used at compile time and doesn’t become a runtime dependency of your application.
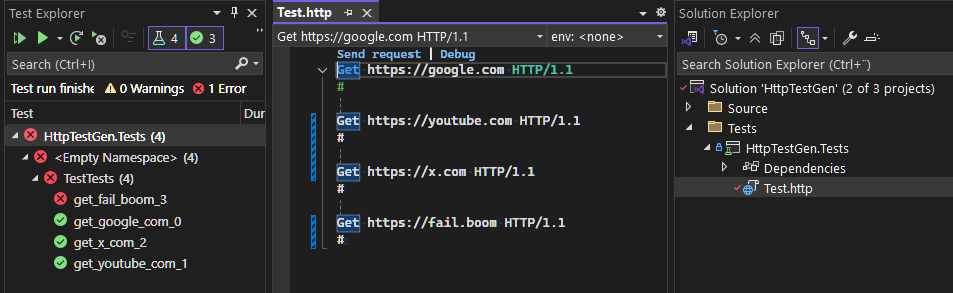
Creating .http Files in Visual Studio
Visual Studio provides excellent support for .http files, making it easy to design and test your APIs interactively before converting them into automated tests.
Basic .http File Syntax
Create a .http file in your test project with HTTP requests. Here’s an example covering common scenarios:
# Simple GET request
GET https://api.example.com/users
# GET request with headers
GET https://api.example.com/users/123
Accept: application/json
Authorization: Bearer your-token-here
# POST request with JSON body
POST https://api.example.com/users
Content-Type: application/json
{
"name": "John Doe",
"email": "john@example.com"
}
# Request with expected status code
GET https://api.example.com/nonexistent
EXPECTED_RESPONSE_STATUS 404
# Request with expected response headers
GET https://api.example.com/data
EXPECTED_RESPONSE_HEADER content-type: application/json
EXPECTED_RESPONSE_HEADER x-custom-header: custom-value
Visual Studio Integration
When working with .http files in Visual Studio, you can:
- Test manually: Use the “Send Request” button to execute requests directly from the editor
- View responses: See formatted JSON, XML, and text responses inline
- Debug requests: Inspect headers, status codes, and response times
- Environment support: Use variables for different environments (development, staging, production)
Assertion Keywords
HttpTestGen implements powerful assertion keywords that allow you to validate API responses automatically. These assertions are embedded directly in your .http files and become part of the generated test code.
Status Code Assertions
Use EXPECTED_RESPONSE_STATUS to validate HTTP status codes:
# Test successful response
GET https://api.example.com/users
EXPECTED_RESPONSE_STATUS 200
# Test not found scenario
GET https://api.example.com/notfound
EXPECTED_RESPONSE_STATUS 404
# Test authentication failure
GET https://api.example.com/protected
Authorization: Bearer invalid-token
EXPECTED_RESPONSE_STATUS 401
Header Assertions
Use EXPECTED_RESPONSE_HEADER to validate response headers:
# Validate content type and caching headers
GET https://api.example.com/api/data
EXPECTED_RESPONSE_HEADER content-type: application/json
EXPECTED_RESPONSE_HEADER cache-control: no-cache
# Validate custom security headers
GET https://api.example.com/secure-endpoint
EXPECTED_RESPONSE_HEADER x-security-token: required
EXPECTED_RESPONSE_HEADER x-rate-limit-remaining: *
Generated Test Code
The source generator automatically creates test methods from your .http files. The generated code is clean, readable, and follows testing best practices.
xUnit Output Example
For the .http file examples above, HttpTestGen would generate:
public class ApiTestsXunitTests
{
[Xunit.Fact]
public async Task get_api_example_com_0()
{
var sut = new System.Net.Http.HttpClient();
var response = await sut.GetAsync("https://api.example.com/users");
Xunit.Assert.True(response.IsSuccessStatusCode);
}
[Xunit.Fact]
public async Task get_api_example_com_1()
{
var sut = new System.Net.Http.HttpClient();
var request = new HttpRequestMessage(HttpMethod.Get, "https://api.example.com/users/123");
request.Headers.Add("Accept", "application/json");
request.Headers.Add("Authorization", "Bearer your-token-here");
var response = await sut.SendAsync(request);
Xunit.Assert.True(response.IsSuccessStatusCode);
}
[Xunit.Fact]
public async Task post_api_example_com_2()
{
var sut = new System.Net.Http.HttpClient();
var content = new StringContent("{\"name\":\"John Doe\",\"email\":\"john@example.com\"}",
System.Text.Encoding.UTF8, "application/json");
var response = await sut.PostAsync("https://api.example.com/users", content);
Xunit.Assert.True(response.IsSuccessStatusCode);
}
[Xunit.Fact]
public async Task get_api_example_com_3()
{
var sut = new System.Net.Http.HttpClient();
var response = await sut.GetAsync("https://api.example.com/nonexistent");
Xunit.Assert.Equal(404, (int)response.StatusCode);
}
[Xunit.Fact]
public async Task get_api_example_com_4()
{
var sut = new System.Net.Http.HttpClient();
var response = await sut.GetAsync("https://api.example.com/data");
Xunit.Assert.True(response.IsSuccessStatusCode);
Xunit.Assert.True(response.Headers.GetValues("content-type").Contains("application/json"));
Xunit.Assert.True(response.Headers.GetValues("x-custom-header").Contains("custom-value"));
}
}
Generated Test Features
The generated tests include:
- Proper HTTP client usage: Each test method creates and uses an
HttpClientinstance - Header handling: Request headers are properly added to HTTP requests
- Content management: Request bodies are converted to appropriate
HttpContenttypes - Assertion integration: Expected status codes and headers become proper test assertions
- Async/await patterns: All HTTP operations use proper async patterns
Project Integration
Integrating HttpTestGen into your project is seamless and requires minimal configuration.
Example Project Structure
MyProject.Tests/
├── MyProject.Tests.csproj
├── api-tests.http
├── user-tests.http
└── integration-tests.http
The source generator will automatically create corresponding test classes:
api-tests.http→ApiTestsXunitTestsorApiTestsTests(TUnit)user-tests.http→UserTestsXunitTestsorUserTestsTests(TUnit)integration-tests.http→IntegrationTestsXunitTestsorIntegrationTestsTests(TUnit)
Development Workflow
The typical development flow with HttpTestGen is:
- Design your API using
.httpfiles in your IDE - Test manually using REST Client extensions or Visual Studio’s built-in HTTP client
- Add assertions for expected behavior using the assertion keywords
- Build project to generate automated tests
- Run tests in CI/CD pipeline
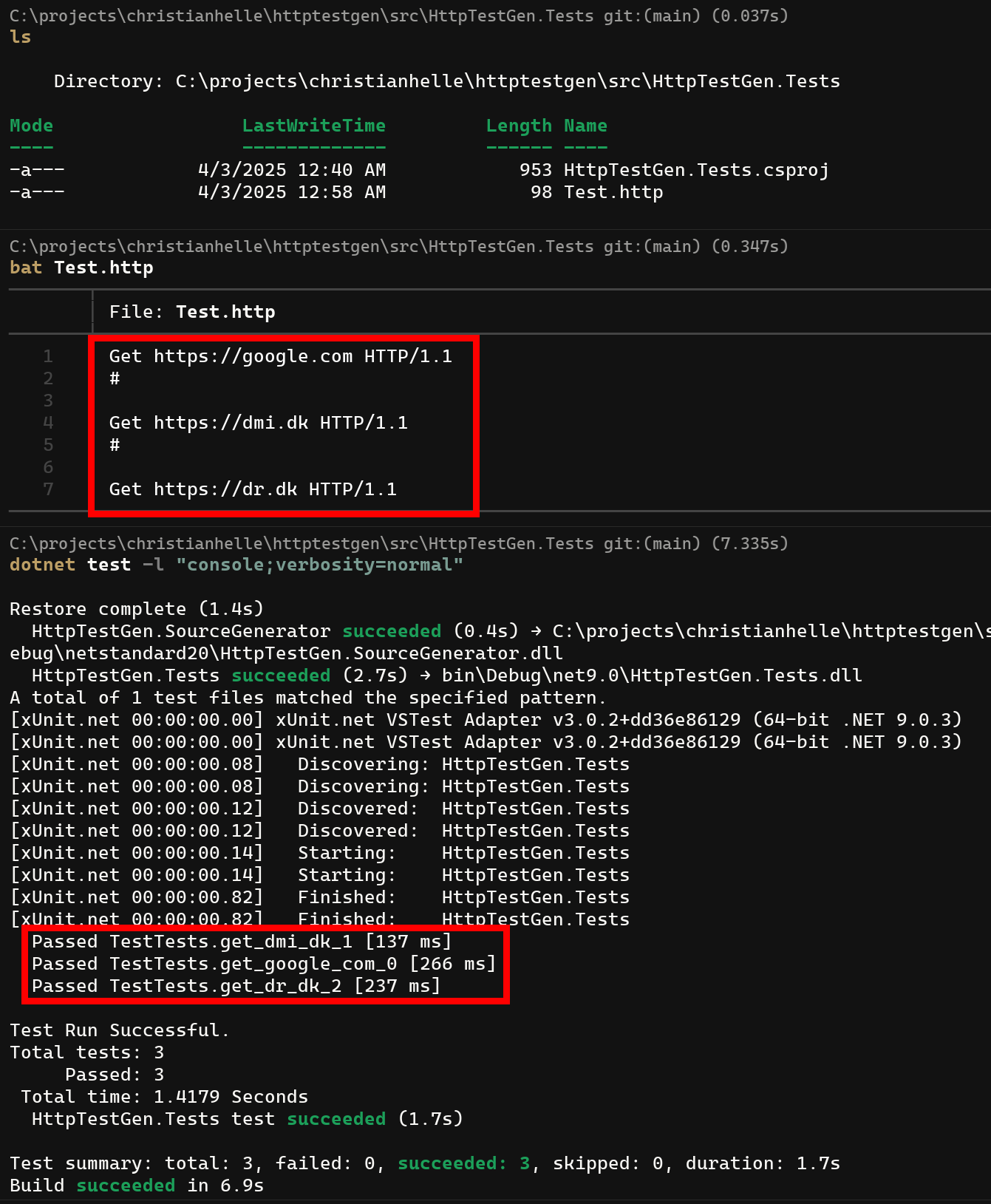
Running Tests
Once your project is built, you can run the generated tests using standard .NET testing tools:
# Run all tests
dotnet test
# Run tests with verbose output
dotnet test --logger:console;verbosity=detailed
# Run specific test class
dotnet test --filter "ApiTestsXunitTests"
Advanced Features
HttpTestGen supports several advanced features for complex testing scenarios.
Multiple Request Bodies
The tool supports various content types for request bodies:
# JSON body
POST https://api.example.com/data
Content-Type: application/json
{
"key": "value"
}
# XML body
POST https://api.example.com/data
Content-Type: application/xml
<root>
<item>value</item>
</root>
# Plain text body
POST https://api.example.com/data
Content-Type: text/plain
This is plain text content
Comments and Documentation
Use # for comments in your .http files to document your tests:
# This tests user authentication
POST https://api.example.com/auth/login
Content-Type: application/json
{
"username": "testuser",
"password": "testpass"
}
# Verify successful login returns token
EXPECTED_RESPONSE_STATUS 200
EXPECTED_RESPONSE_HEADER content-type: application/json
Multiple Requests
Separate multiple requests with blank lines or comments:
GET https://api.example.com/users
# Test user creation
POST https://api.example.com/users
Content-Type: application/json
{
"name": "Test User"
}
# Test user deletion
DELETE https://api.example.com/users/123
Best Practices
Organization and Structure
- Organize by feature: Create separate
.httpfiles for different API endpoints or features - Use descriptive comments: Document what each request tests
- Add assertions: Always include expected status codes and important headers
- Environment variables: Use your IDE’s environment variable support for different environments
- Version control: Commit your
.httpfiles alongside your code
Testing Strategies
Unit Tests vs Integration Tests:
- Unit Tests: Test individual endpoints with mocked dependencies
- Integration Tests: Test complete API flows with real HTTP calls
- Contract Tests: Verify API contracts match expectations
Assertion Patterns:
# Success scenarios
GET https://api.example.com/users
EXPECTED_RESPONSE_STATUS 200
EXPECTED_RESPONSE_HEADER content-type: application/json
# Error scenarios
GET https://api.example.com/users/999999
EXPECTED_RESPONSE_STATUS 404
# Authentication scenarios
GET https://api.example.com/protected
Authorization: Bearer invalid-token
EXPECTED_RESPONSE_STATUS 401
Performance Considerations
HttpTestGen is designed for optimal performance:
- Compile-time generation: Zero runtime overhead
- Incremental builds: Only regenerates when
.httpfiles change - Parallel execution: Generated tests can run in parallel
- Memory efficient: No reflection or dynamic compilation at runtime
Integration with Popular Tools
HttpTestGen works seamlessly with the HTTP File Generator tool I created for generating .http files from OpenAPI specifications, and pairs well with other .NET testing frameworks like Alba and Atc.Test.
Visual Studio Code
HttpTestGen works seamlessly with the REST Client extension for Visual Studio Code, allowing you to design and test APIs interactively before generating automated tests.
JetBrains IDEs
The tool is compatible with the built-in HTTP client in IntelliJ IDEA, WebStorm, and Rider, providing a consistent experience across different development environments.
CI/CD Integration
Generated tests integrate naturally with CI/CD pipelines:
# Example GitHub Actions workflow
- name: Run API Tests
run: dotnet test --filter "HttpTestGen" --logger trx
Conclusion
HttpTestGen represents a significant step forward in .NET API testing, bridging the gap between manual API testing and automated test suites. By leveraging the familiar .http file format that developers already use for interactive API testing, HttpTestGen eliminates the friction between designing APIs and testing them comprehensively.
The tool’s source generator approach ensures zero runtime overhead while providing powerful assertion capabilities that validate not just connectivity, but the correctness of API responses. Whether you’re building microservices, REST APIs, or integration tests, HttpTestGen fits naturally into your development workflow.
The combination of Visual Studio’s excellent .http file support and HttpTestGen’s automatic test generation creates a seamless experience from API design to automated testing. Your .http files become living documentation of your API contracts while simultaneously serving as comprehensive test suites.
Give HttpTestGen a try in your next .NET project and experience how it can streamline your API testing workflow. The tool is open source and available on GitHub, where you can contribute, report issues, or explore the implementation details.
Whether you’re just getting started with API testing or looking to improve your existing testing strategy, HttpTestGen provides a powerful, lightweight solution that grows with your project’s needs.